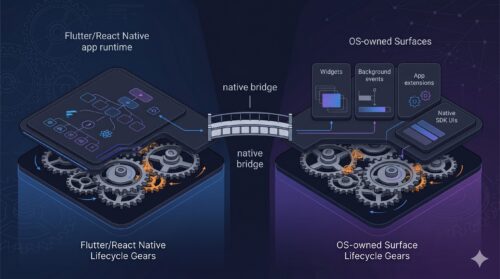
The main cross-platform frameworks have come a long way. Flutter, React Native, and Expo are not toys anymore. For most common native APIs, there is already at least one wrapper, plugin, config option, or known path: location, notifications, camera, permissions, storage, analytics, payments, deep links, crash reporting. The normal native bridge story is mostly solved…. Continue reading
The Native Bridge Is Usually the Easy Part